I recently had a requirement where I needed to extract only SharePoint-related URLs from a large XML sitemap file. The sitemap contained thousands of URLs, and manually filtering them was not practical at all. I specifically wanted to identify URLs that included keywords like “sharepoint” or “share-point” so I could use them for further analysis and content optimization.
At first, I considered opening the XML file and searching manually, but that quickly proved inefficient and error-prone. That’s when I turned to PowerShell. I realized I could automate the entire process — read the sitemap, filter only the relevant URLs using a pattern, and export them into a clean text file within seconds.
In this article, I’ll walk you through the exact PowerShell script I used to extract URLs from an XML sitemap.
Here is what you will learn:
- How to read an XML sitemap file using PowerShell
- How to use regex to extract and filter
<loc>URLs - How to remove duplicate URLs automatically
- How to save the filtered results to a
.txtfile
Prerequisites
Before you begin, make sure you have:
- Windows PowerShell 5.1 or PowerShell 7+
- An XML sitemap file saved locally (e.g., exported from Screaming Frog or your CMS)
- Basic familiarity with running PowerShell scripts
Understanding the XML Sitemap Structure
An XML sitemap follows a standard structure where every URL is wrapped inside a <loc> tag like this:
<urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9">
<url>
<loc>https://www.spguides.com/sharepoint-list-tutorial/</loc>
<lastmod>2026-01-10</lastmod>
</url>
<url>
<loc>https://www.spguides.com/power-automate-basics/</loc>
<lastmod>2026-01-12</lastmod>
</url>
</urlset>
The goal is to extract only the URLs inside <loc> tags that contain the word sharepoint or share-point — regardless of case.
Check out Access to the Path Is Denied
Extract URLs from XML Sitemap Using PowerShell
Here is the complete PowerShell script to extract URLs from an XML sitemap.
# Input and output files
$xmlFile = "C:\Users\fewli\Downloads\XML Sitemap - PowerShell FAQs.xml"
$outputFile = "C:\Users\fewli\Downloads\sharepoint-urls.txt"
# Read XML content as a raw string
$content = Get-Content $xmlFile -Raw
# Extract URLs containing sharepoint or share-point (case-insensitive)
$urls = [regex]::Matches($content, '<loc>(https?://[^<]*(share-point|sharepoint)[^<]*)</loc>', 'IgnoreCase') |
ForEach-Object { $_.Groups[1].Value } |
Select-Object -Unique
# Save to TXT file
$urls | Out-File $outputFile -Encoding UTF8
Write-Host "Found $($urls.Count) URLs."
Write-Host "Saved to: $outputFile"
After I executed the PowerShell script using VS Code, you can see the exact output in the screenshot below:
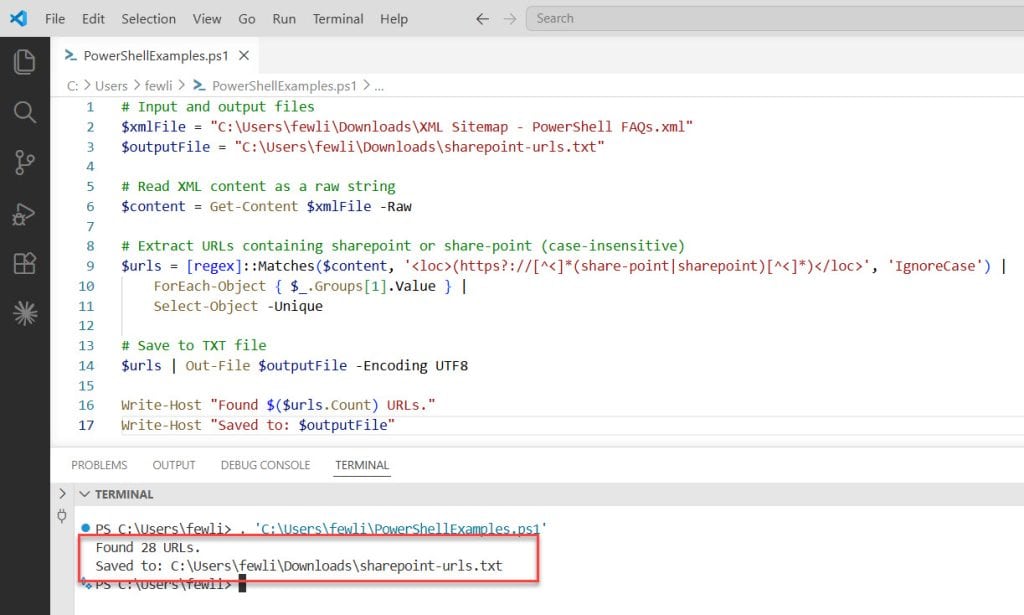
Here is the breakdown of the complete PowerShell script.
Step 1 — Define File Paths
$xmlFile = "C:\Users\fewli\Downloads\XML Sitemap - PowerShell FAQs.xml"
$outputFile = "C:\Users\fewli\Downloads\sharepoint-urls.txt"
Two variables store the full path to your input XML sitemap and the output .txt file where filtered URLs will be saved. Update these paths to match your actual file locations.
Check out How to Convert XML to Table in PowerShell
Step 2 — Read the XML File as Raw Text
$content = Get-Content $xmlFile -Raw
The -Raw parameter reads the entire file as a single string rather than an array of lines. This is important because it ensures the regex engine can match patterns that might otherwise be split across multiple lines, giving you reliable results even on large sitemaps.
Step 3 — Extract Matching URLs with Regex
$urls = [regex]::Matches($content, '<loc>(https?://[^<]*(share-point|sharepoint)[^<]*)</loc>', 'IgnoreCase') |
ForEach-Object { $_.Groups[1].Value } |
Select-Object -Unique
This is the core of the script. Here’s what each part of the regex does:
<loc>— matches the opening<loc>tag literally(https?://— captures URLs starting withhttp://orhttps://[^<]*— matches any character except<(avoids overmatching into the next tag)(share-point|sharepoint)— matches either spelling of “sharepoint”[^<]*— captures the rest of the URL path</loc>— matches the closing tag
[regex]::Matches() returns all matches in the string. The ForEach-Object pipe extracts capture group 1 — the full URL — from each match. Finally, Select-Object -Unique removes any duplicate URLs.
Step 4 — Save Results to a Text File
$urls | Out-File $outputFile -Encoding UTF8
The filtered URLs are piped directly to Out-File, which writes them line by line into the output text file. Using -Encoding UTF8 ensures special characters in URLs are preserved correctly, which matters when working with international domain names or encoded query strings.
Step 5 — Display a Summary in the Console
Write-Host "Found $($urls.Count) URLs."
Write-Host "Saved to: $outputFile"
These two lines give you immediate feedback — the total count of matched URLs and the output file path — so you can verify the script ran successfully without opening the file manually.
How to Run the Script
- Open Windows PowerShell or PowerShell 7 as your current user
- Copy the script into a new file and save it as
Extract-SitemapURLs.ps1 - Update the
$xmlFileand$outputFilepaths to match your environment - Run the script by navigating to its folder and executing:
.\Extract-SitemapURLs.ps1
- Check the console for the URL count and open the output
.txtfile to review results
Check out PowerShell Output to File and Console
Customizing the Script for Other Keywords
The regex pattern is easy to adapt. If you want to extract URLs containing power-automate or powerautomate instead, simply update the alternation group:
'<loc>(https?://[^<]*(power-automate|powerautomate)[^<]*)</loc>'
You can also chain multiple keywords using | inside the group:
'<loc>(https?://[^<]*(sharepoint|power-apps|power-automate)[^<]*)</loc>'
This makes the script reusable for any SEO audit, content migration, or URL analysis task.
Handling Large Sitemaps
For sitemaps with tens of thousands of URLs, the script still performs well because Get-Content -Raw loads the file into memory once and [regex]::Matches() scans it in a single pass.
However, if you’re working with sitemap index files (which link to multiple child sitemaps), you’ll need to first merge the child sitemaps into one file or loop through each file path.
Read ConvertTo-Json in PowerShell
Common Errors and Fixes
- File not found error — Double-check the path in
$xmlFile. UseTest-Path $xmlFileto verify it exists before running the script. - Zero URLs found — Confirm the sitemap uses standard
<loc>tags and that your keyword is actually present in some URLs. Open the XML file in a text editor and search manually to verify. - Output file is empty — This usually happens when
$urlsis null. Wrap theOut-Filecommand with a check:if ($urls) { $urls | Out-File $outputFile -Encoding UTF8 }. - Encoding issues in output — Switch to
-Encoding UTF8BOMif downstream tools expect a BOM (Byte Order Mark) at the start of the file.
Conclusion
This PowerShell script is a simple but powerful tool for anyone working with XML sitemaps at scale. With just a few lines of code, you can filter thousands of URLs by keyword, deduplicate them, and export the results instantly.
Save this script to your toolkit, adjust the regex pattern for your specific keywords, and you’ll have a reusable URL extractor ready for any project.
You may also like the following tutorials:
- Convert JSON to XML using PowerShell
- Convert XML to CSV in PowerShell
- PowerShell Convert XML to Object
Bijay Kumar is an esteemed author and the mind behind PowerShellFAQs.com, where he shares his extensive knowledge and expertise in PowerShell, with a particular focus on SharePoint projects. Recognized for his contributions to the tech community, Bijay has been honored with the prestigious Microsoft MVP award. With over 15 years of experience in the software industry, he has a rich professional background, having worked with industry giants such as HP and TCS. His insights and guidance have made him a respected figure in the world of software development and administration. Read more.
